5. Administrar una BD Relacional¶
5.1. ¿De qué va este tema?¶
En este tema aprenderás, usando el SGBD Relacional PostgreSQL, a:
Administrar una base de datos relacional (o varias)
Realizar el diseño físico de un modelo de datos en SQL
Administrar los diferentes objetos de una BD y usar operaciones CRUD
Se trata de ser capaces de usar un SGBDR (El SGBD PostgreSQL) para administrar tu almacén de datos (o varios).
Documentación Oficial Posgres
Usaremos la documentación oficial de la última versión de Postgres. Puede resultar un poco apabullante en principio y abarca mucho más de lo que veremos aquí, pero te sirve tanto para empezar, como para convertirte en un DBA (formación maestría)
Por esto, cuanto antes te acostumbres a usarla, mejor.
5.2. Clases¶
Está organizado en 8 talleres de unas 3 sesiones de clase. En total unas 24 sesiones de clase más tu trabajo en casa.
La dedicación depende del conocimiento previo, motivación y capacidad de aprendizaje del estudiante para esa sesión en concreto.
Video Introducción
5.2.1. El cliente psql (y otros)¶
Para conectarte, salvo que uses valores predeterminados, necesitas:
Un SGBDR Postgres funcionando
La cadena de conexión, con los parámetros necesarios. Lo habitual: postgresql://equipo:puerto/base_de_datos
Un software cliente para realizar la conexión
El cliente psql
Es un comando (app-psql) con un montón de opciones para:
Especificar la cadena de conexión y conectarte a una BD
Ver las bases de datos disponibles
Ejecutar comandos sql directamente desde un archivo
y varias cosas más (app-psql), sin tener que conectarte directamente a una consola
Además, te ofrece una consola interactiva (PostgreSQL interactive terminal), donde puedes:
Usar SQL directamente (terminando la instrucción en ; o en
\para continuar en otra línea) oUsar comandos propios (backslash comands). Por ejemplo para ver la ayuda con
\ho un montón de información diferente
Además hay multitud de PosgreSQL Clients :
Aunque no exista ninguna BD creada, existe una predeterminada a la que te puedes conectar, puedes ver:
Todas las BD disponibles (
psql -l)Una vez conectado puedes ver una serie de datos del sistema (en tablas especiales -> views). Por ejemplo:
SELECT datname FROM pg_database; SELECT spcname FROM pg_tablespace; SELECT * from pg_settings; SELECT rolname FROM pg_roles;
Y hasta podrías modificar esas tablas del sistema para configurarlo catalogs (no suele ser buena idea)
La creación de una base de datos es muy sencilla (manage-ag-createdb):
Vía SQL : CREATE DATABASE
Vía comando: createdb
Video Clase
Conectándote a la BD
Supongamos que tienes PostgreSQL recién instalado. No hay ninguna BD creada (salvo la predeterminada) y ningun usuario ni roles (salvo los predeterminados). Además, está instalada con los parámetros predeterminados (host: localhost, puerto: 5432, superusuario:postgres que además es el usuario con el que se instaló).
Conéctate al SGDB
¿Qué bases de datos puede servir?
Crea la base de datos prueba1 (Ojo a revisar a qué BD te estás conectando)
Añádele una tabla de ejemplo con al menos dos campos.
Crea la base de datos prueba2
Crea una tabla de ejemplo, con al menos dos campos.
Añade ahora una tabla extra a cada una de ellas
Revisa la información de alguna tabla del sistema (p.ej pg_database , pg_roles o pg_settings)
¿Cómo ves qué tablas tiene cada Base de datos? ¿Y las columnas (campos)?
¿Cuántas bases de datos tiene tu instancia postgres? Hazlo vía psql
Borra las bases de datos creadas una vez terminada la prueba.
5.2.2. Configurando Postgres¶
La configuración puede ser muy compleja y depende de la necesidad concreta
Video Clase
Se puede hacer de diferentes formas:
Usando archivos de configuración
Usando SQL
Usando funciones y tablas específicas del sistema
Archivos de Configuración:
Configuración General (postgresql.conf )
Permite una configuración muy avanzada (runtime-config)
Almacenamiento, conexiones, rendimiento, recursos y más.
Uno muy importante es el directorio físico donde se encuentran los datos (generalmente en $POSTGRES/data)
Autenticación del cliente (pg_hba.conf ). Controla:
Qué equipos (hosts) se pueden conectar
Cómo se autentican los clientes
A qué nombres de usuario aplica
A qué base de datos puede acceder
Una cosa es cómo se autentica el cliente y otra qué puede hacer el usuario (roles y permisos)
Equivalencia de usuarios del sistema y de postgres (Archivo pg_ident.conf )
Una configuración básica puede abarcar:
Definir qué usuarios, desde qué máquinas y a qué bd conectarse
Definir parámetros de uso en memoria, número de conexiones y el tamaño de caché
Además, se pueden configurar parámetros específicos para una BD concreta:
ALTER DATABASE mi_bd SET parametro TO valor;-> manage-ag-config
Configuración de la instancia postgres
¿En qué directorio están los archivos de configuración?
¿Cómo arrancas, paras y/o reinicias el servicio?
¿Donde están los logs para revisar el servicio?
¿En qué parámetro cambiarías la dirección IP y el puerto de escucha?
¿Cómo harías para permitir que se conecten un máximo de 40 clientes?
¿En qué parámetro definimos la cantidad de memoria que va a usar postgres?
Supón que quieres que sólo se pueda conectar pepe, a la base de datos ejemplo, desde localhost, ¿cómo haces?
Supón que quieres que sólo se pueda conectar pepe, a la base de datos ejemplo, usando SSL y sólo desde la dirección IP 200.200.200.200 , ¿cómo haces?
¿Cómo sabes a qué se refiere el parámetro de configuración authentication_timeout?
¿Cómo sabes a qué se refiere el parámetro de configuración shared_buffers?
5.2.3. Creando una BD¶
Una BD es una colección de objetos sql. Creas la estructura y la llenas de objetos.
Creas una BD (manage-ag-createdb):
CREATE DATABASE mi_bd OWNER postgres;
Una vez creada (está vacía, pero creada):
Defines los objetos (la estructura) y restricciones. Por ejemplo
CREATE TABLE ejemplo (un_numero integer UNIQUE, un_text varchar(15) NOT NULL);
Defines contenido (operaciones CRUD). Por ejemplo:
INSERT INTO ejemplo (2, 'dos'); INSERT INTO ejemplo (3, 'tres'); INSERT INTO ejemplo (4, 'cuatro');
Y luego la puedes borrar:
DROP DATABASE mi_bd
Se puede hacer también con comandos de administración en consola del sistema (app-createdb, app-dropdb )
Esquemas en Postgres (ddl-schemas)
Una BD contiene varios esquemas:
El público (public)
El del sistema (pg_catalog)
(opcional). Los creados por el usuario (nombres definidos)
Cada esquema tiene sus propios objetos que se referencian dentro de ese esquema. Equivalente a organizar los objetos en carpetas (directorios)
La principal ventaja es organizar los objetos en una BD para gestionarlos mejor, a nivel de almacenamiento, acceso o seguridad
CREATE SCHEMA myschema; CREATE TABLE myschema.tabla1 (uno varchar(2)); CREATE TABLE tabla1 (uno varchar(4)); -- Esta es otra tabla, la public.tabla1 (en el Schema public) DROP TABLE public.tabla1; select * from myschema.tabla1 ; DROP SCHEMA myschema CASCADE; -- borra el esquema, y todos sus objetos
Tablespaces : varios espacios de almacenamiento
Permite definir un espacio físico donde almacenar los datos
Todas las BD se almacenan en el predeterminado (pg_default), pero puedes crear otros lugares de almacenamiento. Por ejemplo:
CREATE TABLESPACE alternativa LOCATION '/ssd1/postgresql/data'; -- Tiene que existir esa ruta de archivos CREATE TABLE prueba(i integer) TABLESPACE alternativa; -- Creas un objeto y lo asignas a ese espacio de almacenamiento
Y otra opción es separar valores de una misma tabla en varias tablas (partitioned table )
una tabla padre que tiene tablas hijas exclusivas y conjuntas
Se crear la partición según diferentes criterios (ddl-partitioning)
Video Clase
Crear una BD
Crea una base de datos bd1
Con dos esquemas: esquema1 y esquema2
Crea la tabla ejemplo dentro de esquema1
Crea la tabla ejemplo dentro de esquema1
Crea la tabla nueva, ¿en qué esquema se crea?
Borra esquema1.ejemplo
Borra la base de datos creada
¿Qué tablas tiene el esquema pg_catalog?
¿Qué significa la creación de un tablespace?
¿Qué significa el particionado de una tabla?
5.2.4. Diseño Físico¶
Repasa la clase Diseño Físico (con SQL)
Video Clase
Fases del diseño físico:
Modelo de datos. Crear Objetos en la BD
Representación Física. Almacenamiento físico de los datos
Mecanismos de Seguridad. Autorización sobre los objetos
Mejora continua: monitoreo y optimización
Usamos el lenguaje SQL ( Repasar El lenguaje SQL)
Para definir los datos (Lenguaje DDL)
Para definir el acceso a los datos (Lenguaje DCL)
Como control transaccional (Lenguaje DTL)
Para consultar y modificar los datos (Lenguaje DML)
Video Clase
Lo más habitual
Partimos de:
Un diseño lógico relacional en notación CF:
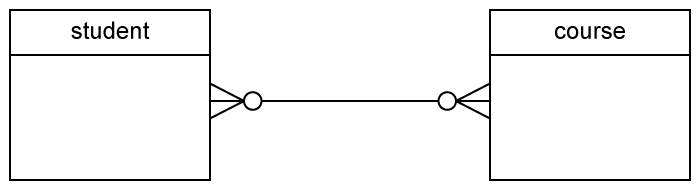
o un grafo relacional :
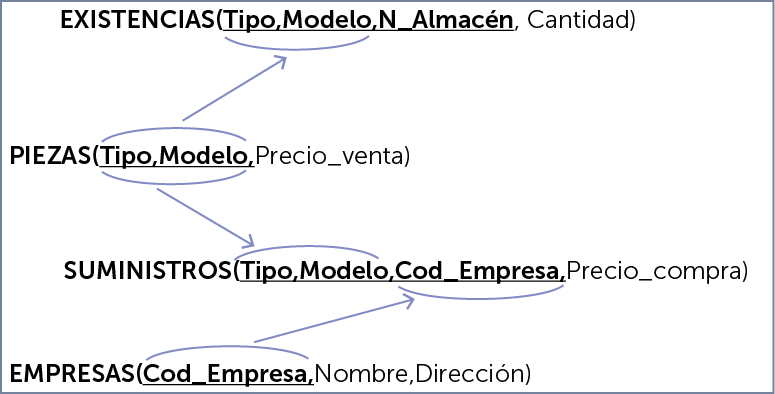
Usamos algunas reglas al trasformar un diseño lógico en diseño físico:
Cada entidad es una tabla (con sus atributos correspondientes)
La claves ajenas se definen según el tipo de relación:
Relaciones 1:1. Una de las tablas tiene un campo que es clave ajena en la otra
Relaciones 1:N. Una de las tablas tiene un campo que es clave ajena en la otra (ojo a los valores nulos)
Relaciones N:M. Una nueva tabla con la relación, y claves foráneas a la tablas que se relacionan. La PK puede ser más compleja.
Se define el comportamiento de las claves ajenas cuando se actualizan o se borran.
El objetivo es tener el modelo de datos en un archivo (modelo.sql en SQL usando las características DDL)
Creación de tablas. Usamos lo más básico, pero puede ser muy avanzado (sql-createtable):
column_constraint: restricciones a nivel de campo
where column_constraint is: [ CONSTRAINT constraint_name ] NOT NULL | NULL | CHECK ( expression ) [ NO INHERIT ] | DEFAULT default_expr | UNIQUE [ NULLS [ NOT ] DISTINCT ] index_parameters | PRIMARY KEY index_parameters
table_contraint: restricciones a nivel de tabla
and table_constraint is: [ CONSTRAINT constraint_name ] { CHECK ( expression ) [ NO INHERIT ] | UNIQUE [ NULLS [ NOT ] DISTINCT ] ( column_name [, ... ] ) index_parameters | PRIMARY KEY ( column_name [, ... ] ) index_parameters | EXCLUDE [ USING index_method ] ( exclude_element WITH operator [, ... ] ) index_parameters [ WHERE ( predicate ) ] | FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELET referential_action ] [ ON UPDATE referential_action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
referential_action: comportamiento de las FK
REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE referential_action ] [ ON UPDATE referential_action ]
Aprendiendo de modelos de datos de otros:
-
create table acs_objects ( object_id integer not null constraint acs_objects_object_id_pk primary key, object_type varchar(1000) not null constraint acs_objects_object_type_fk references acs_object_types (object_type), title varchar(1000) default null, package_id integer default null, context_id integer CONSTRAINT acs_objects_context_id_fk REFERENCES acs_objects(object_id) ON DELETE CASCADE, security_inherit_p boolean default 't' not null, creation_user integer, creation_date timestamptz default current_timestamp not null, creation_ip varchar(50), last_modified timestamptz default current_timestamp not null, modifying_user integer, modifying_ip varchar(50), constraint acs_objects_context_object_un unique (context_id, object_id) );
-
create sequence t_acs_log_id_seq; create view acs_log_id_seq as select nextval('t_acs_log_id_seq') as nextval; create table acs_logs ( log_id integer constraint acs_logs_log_id_pk primary key, log_date timestamptz default current_timestamp not null, log_level varchar(20) not null constraint acs_logs_log_level_ck check (log_level in ('notice', 'warn', 'error', 'debug')), log_key varchar(100) not null, message text not null );
-
DROP SEQUENCE IF EXISTS "public"."multimedia_id_seq"; CREATE SEQUENCE "public"."multimedia_id_seq" INCREMENT 1 MINVALUE 1 MAXVALUE 9223372036854775807 START 409 CACHE 1;
-
BD hubway en Postgres
Usando la Base de datos Hubway, tanto su estructura y los valores, queremos crear una BD en Postgres (hubway_postgres) que sea más estricta. Deberías:
Definir los tipos de datos sql para los campos, teniendo en cuenta los valores
Definir las claves primarias y las foráneas
Añadir alguna restricción puntual a un campo de datos revisando los valores
Una vez creada, revisas la exportacion y la comparas con el diseño sql publicado
BD Ejemplo
Puedes usar cualquier ejemplo de Ejercicios de Diseño de Modelo de Datos por ejemplo. Crear una BD con el ejemplo de García Paraneda
Proyecto Northwind
Usando el Proyecto Northwind crea una BD que puedas utilizar en posgtgres
5.2.5. Modificando la BD¶
Tipos de datos (en Posgres):
Números (datatype-numeric) : integer y numeric(p,s)
Texto (datatype-character): varchar(n)
Fechas (datatype-datetime): timestamp (ojo al problema de localización)
Boolean (datatype-boolean): parece una tontería pero es muy útil (campos directos o calculados)
… y, bueno, muchísimos más -> datatype
Trata de usar estándar SQL (en vez de los específicos del SGBD)
Además se pueden crear tipos de datos propios
Modificar la estructura
Lo ideal es borrar y crear, pero no siempre es posible
Se puede añadir y quitar ddl-alter:
campos (columnas)
restricciones
valores por defecto
tipo de datos
el nombre (renombrar)
Crear una tabla a partir de una consulta (muy útil -> sql-createtableas)
Video Clase
Modificar el contenido (Características DML)
INSERT -> sql_insert / dml-insert
UPDATE -> sql_update/ dml-update
DELETE -> sql_delete/ dml-delete
Tutorial Básico Postgres
En el tutorial básico de posgres puedes practicar con un ejemplo sencillo de:
Creación de tablas
Creación de contenidos
Consultas Sencillas
Consultas enlazando tablas (JOINs). Lo vemos en el siguiente tema
Migración de datos a Postgresql
Realiza una migración completa de la Base de datos Hubway a postgres
Tendrás que ajustar el modelo de datos (más restrictivo)
Tendrás que probar que funciona (con algún registro)
Haces la migración completa y de todos los datos (ojo a posibles errores)
Haces una copia de seguridad de sólo la estructura (sólo el esquema) a estructura-hubway.sql
Haces una copia de seguridad de sólo los datos a datos-hubway.sql
Haces la exportacion completa (dump) para poder ver la diferencia con separar esquema y contenido
Borras la base de datos y la importas
¿Cuánto ocupa en disco el cluster de postgres (en realidad están todas las BD?
Cuando haces una consulta, ¿cual crees que es más rápida? ¿Haciéndolo en Postgres o en SQL?
¿Qué SGBD usarías tú, para esta BD, y porqué?
Ejercicios SQL
Repaso los ejercicios Ejercicios para usar SQL pero usando la BD de hubway.db que tienes en postgres
5.2.6. Redundancia y Normalizacion¶
Redundancia: mismos datos en varios lugares (repetidos)
Problemas actualización: si actualizo un campo, ¿se actualizan los otros?
Problemas de inserción: si inserto un valor, ¿se copia en el otro?
Problemas de borrado: al borrar un dato, ¿lo borro en todas partes?
Solución: Normalización de Bases de Datos
Buscamos minimizar la redundancia y evitar sus problemas
Conceptos previos:
Dependencia Funcional
Propiedades: reflexiva, transitiva, unión, etc
Formas Normales: conjunto de reglas que se tienen que cumplir
Proceso práctico (la normalización y redundancia dependerá del caso de uso):
1FN. Dominio atómico.
2FN. DF completa de PK
3FN. No hay DF transitiva
FNBC.
Y hay más
La normalización implica:
Creación de nuevas tablas
Relacionadas entre sí (FK)
Es decir, la solución al problema de la redundancia suele venir:
Dividir la tabla/s en otras tablas que …
conteniendo los mismos campos
se relacionen entre sí (con integridad referencial).
Y cada tabla tendrá las claves primarias adecuadas
Y las FK para no perder ninguna información
Ejercicios Normalización
Video Clase
Revisando las siguientes tablas:
Ver qué problemas de redundancia pueden tener
Encontrar las dependencias funcionales
Resolver el problema (normalizar)
Puedes probar con estos ejemplos:
Persona (dni, nombre, apellido, fecha de nacimiento)
Cuenta (numero_cuenta, nombre, saldo)
Matricula (dni, nombres, apellidos, asignatura)
Hospital (Nombre_h, Dni_pers, direccion_hosp, fax_hosp, telefono_hosp, dirección_pers, teléfono_pers)
Regala(idRegalo, nombreRegalo, nombrePersona, apellidoPersona, precio, dedicatoria)
Pelicula (Titulo, Nombre_actor, Presupuesto, Fecha_realización, Dirección_actor, Teléfono_actor)
Recuerdos(idFoto, idPersona, nombre, dni, títuloFoto, fecha,monumento, ciudad, antigüedadMonumento)
Aunque en la práctica ya se puede hacer de otra forma, para los ejercicios de normalización no puedes crear campos nuevos ni cambiarles el nombre.
Normalización BD Hubway
Revisa la base de datos Base de datos Hubway
¿Tiene algún tipo de redundancia?
¿Podría tener algún problema de actualización o inserción de datos?
¿Podrías proponer un nuevo diseño?
5.2.7. Dominios, Índices y Vistas¶
Hay más objetos en una BD que las tablas.
Se pueden ver los diferentes objetos con el comando
\dSo\dS+en consola postgres. Mostrará esquema, nombre, tipo y propietario de cada objetoAlgunos objetos pertenecen a un esquema y otros se crean vinculados a otros objetos
Hay diferentes objetos, vemos aquí tres ejemplos: dominios, índices y vistas.
Se crean tipicamente usando CREATE objeto_sql
Dominios (sql-createdomain)
Permite crear un conjunto de valores que cumplen una restricción
Por lo tanto es como un nuevo tipo de datos (pero añadiendo las restricciones de forma modular y amplia)
Se usan como si fueran un tipo de datos nuevo
Son muy fáciles de crear. Por ejemplo:
CREATE DOMAIN numero AS integer NOT NULL check (VALUE > 10); CREATE DOMAIN us_postal_code AS TEXT CHECK ( VALUE ~'^\d{5}$' OR VALUE ~ '^\d{5}-\d{4}$' ); CREATE TABLE ejemplo (id numero, codigo us_postal_code);
Vistas (sql-createview)
Una vista es una tabla temporal como resultado de una consulta (se ejecuta cada vez)
Se busca definir un objeto sql con los datos que interesen para esa necesidad (o usuario) concreto. Al ser un objeto, se pueden definir permisos particulares
Permite tener acceso a parte de los datos para un usuario concreto (define el nivel externo arquitectura ANSI/XPARC):
Vista Vertical: se accede a parte de los campos de la tabla
Vista Horizontal: se accede a parte de los registros (tuplas) de la tabla
Vista Híbrida/Mixta: una mecla de las dos anteriores
Son muy fáciles de crear. Por ejemplo:
CREATE VIEW comedies AS SELECT * FROM films WHERE kind = 'Comedy'; CREATE VIEW pg_comedies AS SELECT comedy, classification FROM comedies WHERE classification = 'PG' WITH CASCADED CHECK OPTION;
Índices (sql-createindex)
Un índice de una BD es cómo un índice de un libro: hace más eficiente la búsqueda de información.
Son un objeto de la BD que permite organizar mucha información para acceder mejor a ella
Se puede organizar esta información usando diferentes algoritmos (indexes-types)
Se crean de forma sencilla (indexes-intro):
Se decide sobre qué columnas (una o varias) se define
… y el tipo de índice a utilizar (puede ser complejo)
Algunos índices se crean automáticamente (por ejemplo sobre las PK) y están asociados a la tabla. Al ver la descripción de la tabla (
\d tabla_a_revisar) verás el índice.Por ejemplo
CREATE INDEX test_idx ON test (id); CREATE INDEX test1_id_index ON test1 (id); CREATE INDEX test2_mm_idx ON test2 (major, minor);
Video Clase
Es interesante analizar los índices (y consultas) usando EXPLAIN ANALYZE (using-explain): Es un monitoreo del rendimiento del índice (o la consulta).
Creación de objetos SQL
Crea un dominio llamado velocidad que sólo permita valores enteros entre el 0 y el 220
Crea un dominio llamado matr que sólo permite valores de matrículas españolas
Crea la tabla coche(id, nombre, matric, velocidad) teniendo en cuenta los dominios creados anteriormente
Añade 10 registros a tu tabla y trata de introducir algún dato que no cumpla con las restricciones del dominio, ¿qué pasa?
Crea una vista (vista_1) con sólo las matrículas y nombre de todos los coches (vista vertical)
Crea una vista (vista_2) con el id y nombre de los coches, pero que cumplan alguna condición (vista vertical y horizontal)
¿Qué índices se han creado de forma predeterminada para esa tabla? ¿Cómo lo puedes saber?
Crea un índice sobre el campo nombre y matric . ¿Qué índices hay creados ahora sobre esa tabla?
¿Se te ocurre algún tipo de consulta que harás de forma frecuente? ¿Cómo sería un índice que lo refleje?
(Pro) ¿Sabrías como analizar la consulta antes y después de la creación de tu índice (para reflejar si ha mejorado el rendimiento)
Uso de EXPLAIN sobre BD Hubway
Un trabajo extra podría ser trabajar con Base de datos Hubway para analizar si el uso de algún tipo de índice permite mejorar las consultas
5.2.8. Seguridad en la BD (y en el SGBDR)¶
Seguridad es un concepto y un sistema complejo:
Debe existir algún tipo de planificación y control (Plan de Seguridad)
Lo ideal es tener una auditoría externa
Existen diferentes niveles de protección (en el SGBDR):
A nivel del sistema de archivos (sólo accesible como usuario postgres)
A nivel de acceso de clientes (vía archivo de configuración pg_hba.conf)
A nivel de gestión de usuarios (roles)
A nivel de autorización sobre los objetos SQL
A nivel del diseño lógico y físico: integridad, control transaccional y encriptado (datos y/o conexiones)
Hay también un aspecto importante que es el aspecto legal de la protección de los datos almacenados
Control de Acceso
Quien (roles): Se define quien puede acceder (al menos el superusuario, típicamente
postgres)A qué (objetos): objeto de la base de datos (no sólo tablas)
Cómo (privilegios): qué permisos tiene ese usuario sobre un objeto
Roles (y usuarios) sql-createrole
Tipos de usuarios:
Usuario BD no es lo mismo que Usuario SO (pero suelen coincidir en nombre)
Al menos un superusuario (superuser)
Y cada objeto debe tener al menos un propietario (owner).
Crear un objeto te convierte en su propietario
Postgres usa roles (database-roles) para todas las BD (no en cada una, es para todo el sistema).
Crear un usuario es lo mismo que crear un rol con el atributo LOGIN (se puede conectar)
Cada rol puede tener diferentes características (role-attributes)
Y … diferentes privilegios
Ejemplo de creación:
CREATE ROLE pepe LOGIN; CREATE ROLE lupe WITH LOGIN PASSWORD 'guadalupe' VALID UNTIL '2005-01-01'; CREATE ROLE admin WITH CREATEDB CREATEROLE;
Privilegios (ddl-priv)
Hay diferentes tipos de privilegios que se pueden asignar a un usuario
De forma predeterminada el propietario (owner) es quien crea el objeto (y tiene permisos sobre él)
De forma predeterminada existe el rol PUBLIC
Se gestionan sobre un objeto y un rol concreto:
GRANT (sql-grant). Para asignar privilegios (sobre BD o para roles)
REVOKE (sql-revoke). Para quitarlos
Por ejemplo:
GRANT INSERT ON films TO PUBLIC; GRANT ALL PRIVILEGES ON kinds TO manuel; GRANT admins TO joe; REVOKE INSERT ON films FROM PUBLIC; REVOKE ALL PRIVILEGES ON kinds FROM manuel; REVOKE admins FROM joe;
Se pueden asignar roles a usuarios (crear grupos) -> role-membership. Por ejemplo:
CREATE ROLE joe LOGIN INHERIT; CREATE ROLE admin NOINHERIT; CREATE ROLE wheel NOINHERIT; GRANT admin TO joe; GRANT wheel TO admin; DROP ROLE admin; DROP ROLE wheel;
Para ver roles y privilegios en un objeto SQL puedes usar el comando
\dp.
Video Clase
Usuarios y Privilegios en Postgres
¿Qué usuarios hay en el sistema?
¿Quién es el usuario administrador?
Añade el usuario pepe
Añade el usuario juan, con clave juan
Crea un rol que pueda crear bases de datos, pero no roles (usuarios)
Crea dos vistas (vista1 y vista2)
Pepe sólo puede consultar la vista1
Juan tiene todos los privilegios sobre la vista2
¿Qué problema plantea en la conexión, tener tantos usuarios?
Borra los roles y usuarios y vuelve a la situación original ¿Qué implicaciones tiene?
Deja la configuración de tu entorno de desarrollo para que puedas entrar desde tu usuario, es decir, no trabajar como usuario postgres.